DSPs, BRAMs and a pinch of logic: new recipes for AES on FPGAs by
Saar Drimer, Computer Laboratory, University of Cambridge, UK
Tim Güneysu, Horst Görtz institute for IT security, Ruhr University Bochum, Germany
Christof Paar, Horst Görtz institute for IT security, Ruhr University Bochum, Germany
(Presented at Field-Programmable Custom Computing Machines, 14 April 2008)
Abstract:
We present an AES cipher implementation that is based on the BlockRAM and DSP units embedded within Xilinx's Virtex-5 FPGAs. An iterative "basic" module outputs a 32 bit column of an AES round each clock cycle, with a throughput of 1.76 Gbit/s when processing two 128 bit inputs. This construct is replicated four times for a 128 bit datapath for a full AES round with 6.21 Gbit/s throughput when processing eight inputs. Finally, the "round" module is replicated ten times for a fully unrolled design that yields over 55 Gbit/s of throughput. The combination and arrangement of the specialized embedded functions available in the FPGA allows us to implement our designs using very few traditional user logic elements such as flip-flops and lookup tables, yet still achieve these high throughputs. The complete source code for these designs is made publicly available for use in further research and for replicating our results. Our contribution ends with a discussion of comparing cipher implementations in the literature, and why these comparisons can be meaningless without a common reporting style, platform, or within the context of a specific constrained application.
Here you will find the Verilog source code for the three AES designs described in the above paper
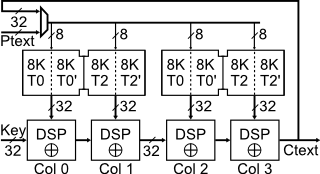
In the paper we describe three variants for an AES implementation on Xilinx Virtex-5 devices: "basic", "round", and "unrolled". Supplied here is the Verilog code for these designs and XFLOW commands for replicating the results we report, which are summarized in the table below.
The results were achieved using XST and ISE version 9.2i.03, so if you compile the code using a different version, then you may get different results (might even exceed them). You will need to download the zip file below and use the command-line XFLOW program that is part of the ISE suite of tools.
| design | slices | LUTs | FFs | BRAMs | DSPs | freq. | throughput |
|---|---|---|---|---|---|---|---|
| basic | 93 | 245 | 274 | 2 | 4 | 550 MHz | 1.76 Gbit/s (2 inputs) |
| round | 277 | 204 | 601 | 8 | 16 | 485 MHz | 6.21 Gbit/s (8 inputs) |
| unrolled | 428 | 672 | 992 | 80 | 160 | 430 MHz | 55 Gbit/s |